지도 미세 조정
LLM이 사용자의 목적에 맞는 적절한 응답을 내놓기 위해서는 지도 미세조정(supervised fine-tuning)이 필요하다. 비록 미세조정 되지 않은 pre-trained LLM 모델도 엄청나게 많은 데이터(Llama-2의 경우 약 10TB의 txt)를 이용하여 사전학습 된 것이기에 대부분의 문제에서 강력한 성능을 보인다. 하지만 LLM이 사용되길 원하는 분야가 아주 마이너하거나 데이터 수집이 어려운 분야라면, 직접 미세조정을 통해 더 우수한 모델을 구축할 수 있을 것이다.
지도 미세조정에 사용하는 데이터셋을 지시 데이터셋(Instruction dataset)이라 부른다. 2023년 공개된 Llama의 추가학습 버전인 Alpaca를 학습하는 데 사용된 알파카 데이터셋을 살펴보도록 한다.
예시 1
Instruction: "Explain the process of photosynthesis."
Input: ""
Response: "Photosynthesis is the process by which green plants, algae, and some bacteria convert light energy, usually from the sun, into chemical energy stored in molecules like glucose. During photosynthesis, plants take in carbon dioxide from the air and water from the soil. Using sunlight as energy, chlorophyll in the plant cells converts these ingredients into glucose and oxygen. The plant uses glucose for energy and growth, and releases oxygen as a byproduct."
예시 2
Instruction: "Translate the following English sentence to French."
Input: "Where is the nearest hospital?"
Response: "Où se trouve l'hôpital le plus proche?"
예시 3
Instruction: "Summarize the following paragraph."
Input: "The water cycle is the continuous movement of water within the Earth and atmosphere. It includes processes such as evaporation, condensation, precipitation, and runoff. Water changes from liquid to vapor and back to liquid in various stages as it moves through the cycle."
Response: "The water cycle describes the continuous movement of water on Earth, involving evaporation, condensation, precipitation, and runoff."
<ChatGPT를 통해 만들어 낸 예시이므로 실제 데이터와 다를 수 있음>
알파카 데이터셋은 Instruction, Input, Response라는 세 가지 필드로 구성된다.
- Instruction : 모델이 수행해야 할 작업에 대한 설명 (ex 영어를 한국어로 번역해줘)
- Input : 모델이 답변을 수행하는 데 필요한 데이터 (ex This is banana)
- Response : 모델이 Instruction, Input에 맞춰 생성해야 하는 답변 (ex 이건 바나나다.)
(알파카 데이터셋의 목적이 Llama 모델을 이용하여 Instruction Tuning을 수행하기 위함이다. 즉, Llama에 알파카 데이터셋을 이용하여 추가학습 한 것이 바로 알파카 모델.)
더하여, 해당 데이터셋을 만든 스탠포드 연구팀은 52000개의 데이터셋을 구축했는데, 사람이 만들어낸 데이터가 아닌 GPT-3를 이용하여 만들어 낸 데이터를 사용했다. 더 정확히는 연구팀이 175개의 프롬프트를 작성하고, 이를 GPT-3에 입력하여 52000개의 Instruction-Response fair를 자동 생성한 후 Llama를 학습하는 데 사용했다.
좋은 데이터셋이 갖춰야 할 조건
LLM을 학습함에 있어 좋은 데이터셋을 구성하려면 다양성, 품질, 규모 등 여러 조건을 고려해야 한다. 딥러닝 모델의 성능은 입력되는 데이터셋이 얼마나 잘 갖추어졌냐에 의존한다. 따라서 좋은 데이터셋을 갖추기 위한 조건을 알아보도록 한다.
Less Is More for Alignment
- 2023년 메타에서 발표한 논문이다.
- LLM에서 Alignment란 모델의 행동과 출력을 사용자의 기대에 맞추는 작업으로 즉, AI 모델이 사용자가 의도한 방식대로 미세조정 되는 것을 의미한다. (사용자의 특수한 목적에 맞춘 대답을 생성하게 하거나, 불필요한 대답을 생성하지 않도록 하는 것)
- 해당 논문에서는 파라미터 개수가 65B(650억)개인 LLaMA 모델을 단 1000개의 지시 데이터셋으로 정렬한 모델인 LIMA를 발표했다.
- LLM 모델을 학습하는 데는 아주 큰 용량의 학습 데이터가 필요하지만 (라마 2의 경우 약 10TB), 이미 사전학습 된 모델을 정렬하는 데는 1000개의 데이터셋 만으로도 정렬이 가능하다는 것이다.
- 심지어는 52,000개의 데이터셋으로 정렬한 알파카 모델보다 LIMA의 응답 품질이 더 뛰어났다.
- 따라서 단순히 데이터의 양을 늘리는 것 보다는 데이터의 다양성과 품질이 모델 성능 향상에 큰 도움이 된다는 것.
Textbooks Are All You Need
- 2023년 마이크로소프트에서 발표한 논문이다.
- 지시 데이터셋의 품질을 높이면 더 작은 데이터셋, 더 작은 모델로도 높은 성능을 달성할 수 있다고 주장
- 코드 생성 모델인 Phi를 정렬하는 데 있어, 교육적 가치가 낮은(불필요한) 코드는 제거하고, 교육적 가치가 높은(핵심이 담긴)코드만 선별하여 사용함으로써 더 적은 데이터셋으로 높은 성능을 확보함.
- 작은 규모의 데이터셋이라도 모델이 지시사항의 형식을 인식하고 답변하도록 데이터셋을 구축해야 함.
- 지시사항이 다양한 형태이고 답변의 품질이 높을수록 모델의 답변 품질도 높아질 것이다.
선호 데이터셋
- OpenAI의 ChatGPT는 개발 초기에 폭탄 제조법이나 차별적인 답변 등 바람직하지 않은 답변을 종종 했었다.
- 이를 해결하기 위해 ChatGPT는 하나의 질문에 여러 답변을 생성한 후, 생성한 답변에 대해 사용자의 평가를 받게 되었다.
- 예를 들어 A, B, C 세 개의 답변을 내놓았을 때 사용자의 선호도가 A>B>C라면, 이를 기반으로 선호 데이터셋을 구축하고 리워드 모델이 이를 학습하여 A를 우선적으로 답변으로 내놓게 만든다.
GPU 효율적인 학습
직전 게시글의 실습 예제를 진행하며 느낀 것 중 하나는, LLM 모델을 학습하는 데 소모되는 컴퓨팅 자원과 시간자원이 장난 아니라는 것이다. 실습에서는 단 10,000개의 데이터만을 사용하여 헤드 부분만 미세조정 했음에도 코랩 T4 기준 1epoch에 대략 13분이 소요되었다. 따라서 한정된 GPU 자원을 더 효율적으로 사용할 수 있는 방안에 대해서 알아본다.
딥러닝 모델의 데이터 타입
- 컴퓨터에서는 일반적으로 소수 연산을 위해 32bit 부동소수점(float32)을 사용한다. 세밀한 계산이 필요한 경우에는 float64를 사용한다.
- 부동소수점을 나타내는 비트의 수가 커질수록 표현 범위가 세밀해지며, 더 긴 소숫점 범위를 나타낼 수 있다.
- 파라미터가 nn억 개인 LLM에는 행렬 연산을 위한 nn억 개의 숫자가 저장되어 있는데, 어떤 데이터 타입을 사용하느냐에 따라 모델의 용량이 달라진다.
- 과거에는 float32 형식을 사용하여 딥러닝 모델을 저장했지만, 모델의 용량이 점점 더 커지면서 감당이 안되기 시작했다. 따라서 최근에는 주로 16비트 형식인 bf16, fp16을 주로 사용한다.
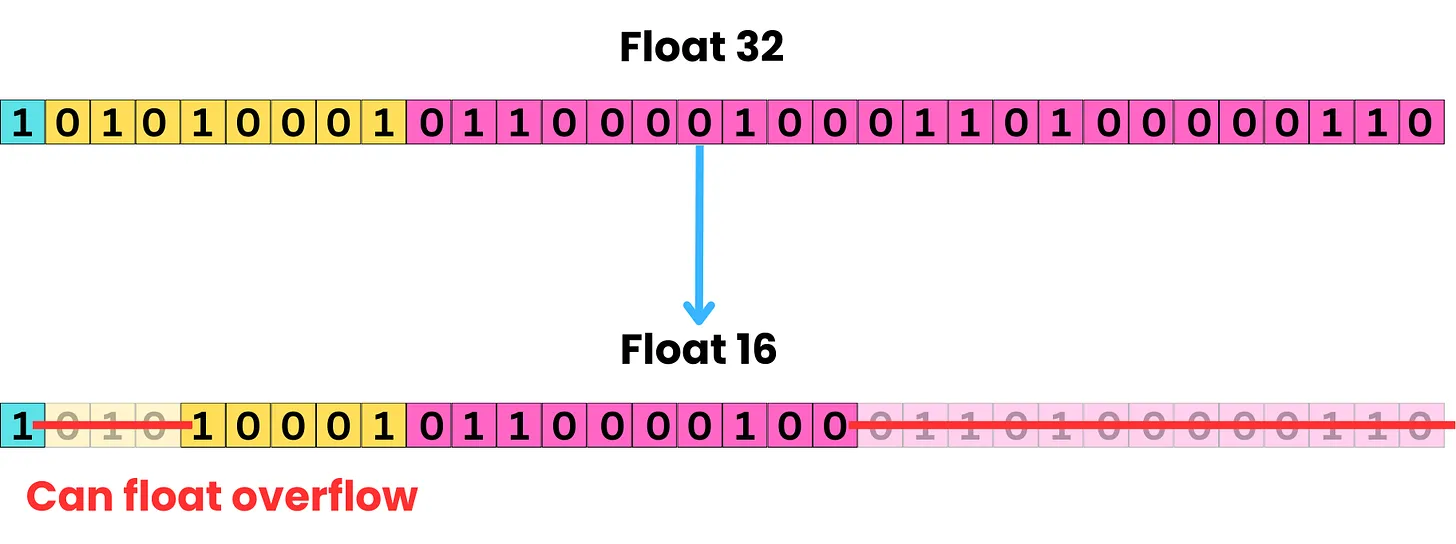
어떤 딥러닝 모델의 파라미터 수가 10억개이고, bf16 데이터 타입으로 저장이 되어있을 때 해당 모델의 용량 계산 과정은 다음과 같다.
- bf16 (bfloat16) 데이터 타입은 16비트, 즉 2바이트를 사용
- 따라서 총 필요한 메모리는 20억 바이트
- 20억 바이트를 GByte 단위로 나타내려면 1024로 세 번 나눠준다. (1024로 한 번씩 나눌 때마다 KB, MB, GB)
-
- 2,000,000,000 바이트
- = 1,953,125 킬로바이트 (KB)
- ≈ 1,907.35 메가바이트 (MB)
- ≈ 1.86 기가바이트 (GB)
따라서 어떤 LLM 모델의 이름이 <냠냠-70B>라면, 해당 모델은 700억 개의 파라미터를 가지며 (16bit 형식으로 저장되었을 시) 대략 70 x 2 = 140GB의 용량을 갖는다.
데이터 양자화
fp32를 이용하여 각 데이터를 32bit 단위로 표현하면 넓은 범위의 수를 세밀하게 표현할 수 있어 모델의 성능이 향상될 수 있지만, 모델의 용량이 너무 크다. 반면, fp16로 변환하면 모델의 용량은 절반으로 줄지만 fp32가 담고있던 정보가 소실될 수 있기에 모델의 성능이 저하된다. 따라서 더 적은 비트로 데이터를 저장하면서도 원본 데이터의 손실을 최대한 줄이는 것이 양자화의 목적이다.
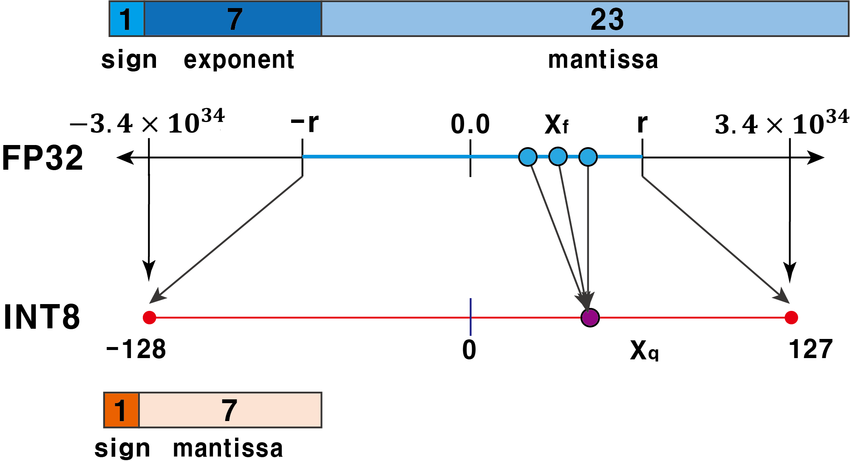
위 그림처럼 fp32는 최대 $3.4\times10^{34}$까지 표현이 가능하지만, int8은 127까지만 표현이 가능하다. 이때 int8으로 데이터 형식을 변환하면서도 데이터 손실을 막기 위해 다음과 같은 방식을 적용할 수 있다.
- 존재하는 데이터의 최대값 범위로 양자화한다. 기존 데이터의 absmax가 127 미만이면, int8을 적용해도 데이터 손실이 없을 것이다.
- 위 방법은 대부분의 경우에 유효하지만, absmax 값을 매우 크게 만드는 outlier가 존재하는 경우에는 효력이 없다. 이 경우에는 데이터를 K개씩 묶은 후, 각 묶음 안에서만 absmax를 구하고 변환을 수행하여 이상치와 함께 묶인 K개의 데이터에만 이상치가 영향을 미친다.
메모리 사용량 측정
허깅페이스에서 불러오는 모델들이 실제로 GPU 메모리를 얼마나 사용하는지 측정해보도록 한다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def print_gpu_utilization():
if torch.cuda.is_available():
used_memory = torch.cuda.memory_allocated() / 1024**3
print(f"GPU 메모리 사용량 : {used_memory:.3f} GB")
else:
print("런타임 유형을 GPU로 변경하세요")
def load_model_and_tokenizer(model_id, peft=None):
tokenizer = AutoTokenizer.from_pretrained(model_id)
if peft is None:
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto",
device_map={"":0})
print_gpu_utilization()
return model, tokenizer
model_id = "EleutherAI/polyglot-ko-1.3b"
model, tokenizer = load_model_and_tokenizer(model_id)
print("모델 파라미터 데이터 타입: ", model.dtype)
위 예제에서는 "EleutherAI/polyglot-ko-1.3b" (https://huggingface.co/EleutherAI/polyglot-ko-1.3)라는 한국어 LLM 모델의 GPU 사용량을 측정한다. 그 결과는 아래와 같았다.
GPU 메모리 사용량 : 7.726 GB
모델 파라미터 데이터 타입: torch.float16
LLM 모델이 학습 과정에서 사용하는 GPU 메모리를 더 자세히 분석해보면 모델 자체가 사용하는 메모리, Gradient(역전파), Optimizer, Forwarding로 나눌 수 있다. 따라서 각 단계에서 GPU 메모리를 얼마나 사용하고 있는지 확인해보도록 한다.
from transformers import AdamW
from torch.utils.data import DataLoader
def estimate_memory_of_gradients(model):
total_memory = 0
for param in model.parameters():
if param.grad is not None:
total_memory += param.grad.nelement() * param.grad.element_size()
return total_memory
def estimate_memory_of_optimizer(optimizer):
total_memory = 0
for state in optimizer.state.values():
for k, v in state.items():
if torch.is_tensor(v):
total_memory += v.nelement() * v.element_size()
return total_memory
def train_model(model, dataset, training_args):
if training_args.gradient_checkpointing:
model.grdient_checkpointing_enable()
train_dataloader = DataLoader(dataset, batch_size=training_args.per_device_train_batch_size)
optimizer = AdamW(model.parameters())
model.train()
gpu_utilization_printed = False
for step, batch in enumerate(train_dataloader, start=1):
batch = {k: v.to(model.device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss = loss / training_args.gradient_accumulation_steps
loss.backward()
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
gradients_memory = estimate_memory_of_gradients(model)
optimizer_memory = estimate_memory_of_optimizer(optimizer)
if not gpu_utilization_printed:
print_gpu_utilization()
gpu_utilization_printed = True
optimizer.zero_grad()
print(f"옵티마이저 상태의 메모리 사용량: {optimizer_memory / (1024 ** 3):.3f} GB")
print(f"그레이디언트 메모리 사용량 : {gradients_memory / (1024 ** 3):.3f} GB")
import numpy as np
from datasets import Dataset
def make_dummy_dataset():
seq_len, dataset_size = 256, 64
dummy_data = {
"input_ids" : np.random.randint(100, 30000, (dataset_size, seq_len)),
"labels" : np.random.randint(100, 30000, (dataset_size, seq_len))
}
dataset = Dataset.from_dict(dummy_data)
dataset.set_format("pt")
return dataset
import gc
def cleanup():
if 'model' in globals():
del globals()['model']
if 'dataset' in globals():
del globals()['dataset']
gc.collect()
torch.cuda.empty_cache()
from transformers import TrainingArguments, Trainer
def gpu_memory_experiment(batch_size,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
model_id="EleutherAI/polyglot-ko-1.3b",
peft=None):
print(f"배치 크기: {batch_size}")
model, tokenizer = load_model_and_tokenizer(model_id, peft=peft)
if gradient_checkpointing == True or peft == 'qlora':
model.config.use_cache = False
dataset = make_dummy_dataset()
training_args = TrainingArguments(
per_device_train_batch_size = batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=gradient_checkpointing,
output_dir="./result",
num_train_epochs=1
)
try:
train_model(model, dataset, training_args)
except RuntimeError as e:
if "CUDA out of memory" in str(e):
print(e)
else:
raise e
finally:
del model, dataset
gc.collect()
torch.cuda.empty_cache()
print_gpu_utilization()
cleanup()
print_gpu_utilization()
for batch_size in [4, 8, 16]:
gpu_memory_experiment(batch_size)
torch.cuda.empty_cache()
위 예제에서는 배치 크기를 4, 8, 16으로 변화시키며 GPU 메모리 사용량을 측정한다. 그 결과는 다음과 같다.
- 배치 크기 4 : 13.044 GB
- 배치 크기 8 : 13.477 GB
- 배치 크기 16 : 14.341 GB
옵티마이저 상태의 메모리 사용량과 그레이디언트 메모리 사용량은 배치크기에 상관 없이 각각 4.961 GB, 2.481 GB로 동일하게 측정되었다. 즉, 메모리 배치 크기는 옵티마이저와 그레이디언트 메모리 사용량에는 영향을 주지 않지만, 순전파 단계에서 영향을 준다는 사실을 알 수 있다.
'딥러닝' 카테고리의 다른 글
| [LLM] 4. 효율적인 GPU 사용, 분산 학습, LoRA, QLoRA (1) | 2025.01.28 |
|---|---|
| [LLM] 2. 허깅페이스 트랜스포머 모델 학습하기 (0) | 2024.11.01 |
| [LLM] 1. 임베딩, 어텐션, 트랜스포머 모델들 (1) | 2024.11.01 |
| 14. LSTM (Long Short Term Memory) 개념 + GRU (3) | 2023.11.15 |
| 13. RNN 코드실습 (0) | 2023.10.31 |



