허깅페이스란?
2017년 트랜스포머 아키텍처가 세상에 공개된 이후, BERT와 GPT등 트랜스포머를 기반에 두면서도 구현 방식이 상이한 자연어 처리 모델들이 쏟아져 나왔다. 각 모델들의 활용법 또한 다르기 때문에, 사용자가 각 모델들의 활용법을 숙지하는 데 시간이 제법 소요되는 상황이 발생한 것. 이에 따라 각 모델의 개발/사용이 지연되기도 했다.
이러한 배경 속에서 Hugging face팀은 트랜스포머 라이브러리를 개발했는데, 쉬운 인터페이스로 트랜스포머 기반의 모델을 활용할 수 있도록 하였다. 이를 통해 우리는 트랜스포머 기반 모델을 손쉽게 사용할 수 있고, 심지어는 나만의 데이터로 학습시키는 것 또한 가능하다. (트랜스포머 기반 뿐만 아니라, 시중에 공개되어 있는 매우 다양한 종류의 딥러닝 모델을 불러와 사용할 수 있다.)
허깅페이스를 사용하는 코드는 아래와 같다.
from transformers import AutoModelForCausalLM, AutoTokenizer
text = 'What is Huggingface Transforemrs?'
# GPT-2 모델
gpt2_model = AutoModelForCausalLM.from_pretrained('gpt2')
gpt2_tokenizer = AutoTokenizer.from_pretrained('gpt2')
input_ids = gpt2_tokenizer(text, return_tensors='pt').input_ids
generated_ids = gpt2_model.generate(input_ids, max_length=50)
generated_text = gpt2_tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(generated_text) # GPT-2가 생성한 텍스트 출력
print 결과 ' Huggingface Transforemrs is a tool that allows you to create a new face for your website. It is a simple tool that allows you to create a new face for your website' 라는 응답이 돌아왔다.
허깅페이스 사용하기
허깅페이스에서 지원하는 모델은 크게 body / head로 구분할 수 있다. 예를 들어 서로 다른 문제가 여러 개 존재한다고 할 때, BERT 모델을 하나의 body로 사용하되 head를 교체하며 텍스트 분류, 토큰 분류 등 서로 다른 문제에 대응할 수 있다.
모델 바디를 불러와본다.
from transformers import AutoModel
model_id = 'klue/roberta-base'
model = AutoModel.from_pretrained(model_id)
transforemrs의 AutoModel 클래스는 모델 바디를 불러오는 클래스이며, 해당 클래스의 from_pretrained 메소드에 입력되는 model_id에 해당하는 모델 바디를 불러오게 된다.
model_id에는 경로를 입력하게 되는데, 허깅페이스의 모델 주소를 입력하면 자동으로 허깅페이스의 모델을 불러오게 되며, 로컬 경로를 지정해주는 경우 사용자의 로컬 모델을 불러온다. 여기서는 모델 아이디에 허깅페이스의 RoBERTa를 설정했다.
이번에는 헤드+바디 일체형 모델을 불러와본다. (여기서는 텍스트 분류 헤드가 달린 모델을 불러온다.)
from transformers import AutoModelForSequenceClassification
model_id = 'SamLowe/roberta-base-go_emotions'
classification_model = AutoModelForSequenceClassification.from_pretrained(model_id)
여기서는 'roberta-base-go_emitons' 라는 모델을 불러왔는데, 이 헤더 모델은 입력 문장이 어떤 emotion을 나타내는지 분류한다. roberta-base는 모델의 바디가 roberta라는 것이고, go_emotion은 해당 모델의 헤더가 emotion 분류 작업을 수행한다는 것을 간략하게 명시하는 것이다. 해당 헤더 모델이 분류하는 class는 model.config 명령어를 통해 다음과 같이 확인할 수 있다.

이번에는 모델의 바디만 불러와보도록 한다.
from transformers import AutoModelForSequenceClassification
model_id = 'klue/roberta-base'
classification_model = AutoModelForSequenceClassification.from_pretrained(model_id)
이런식으로 모델의 바디 부분만 불러오면 다음과 같은 경고문이 뜬다.
Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at klue/roberta-base and are newly initialized: ['classifier.dense.bias', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.out_proj.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
해석해보자면 바디 부분은 roberta-base에서 가져왔지만, 헤더를 불러오지 않았기 때문에 분류 헤드를 랜덤으로 초기화했다는 것이다. 따라서 분류 헤드가 전혀 학습되지 않은 상태가 되기 때문에, 해당 모델을 사용해서 곧바로 분류 작업을 수행하는 것은 불가능하다. 사용자가 직접 헤더를 학습시켜 주어야 한다!
토크나이저 활용
토크나이저(Tokenizer)는 입력된 텍스트를 토큰 단위로 분할하고, 나눠진 각 토큰을 토큰 ID로 변환한다. 또한, 필요한 경우에 특수 토큰을 추가하기도 한다. 토크나이저는 분할된 토큰을 ID로 변환하기 위해서 학습데이터를 통해 어휘 사전을 구축하기 때문에, 일반적으로 모델과 함께 저장되며 허깅페이스 모델 ID를 통해 불러올 수 있다.
토크나이저를 불러오고, 불러온 토크나이저에 대한 정보를 살펴보도록 한다.
from transformers import AutoTokenizer
model_id = 'klue/roberta-base'
tokenizer = AutoTokenizer.from_pretrained(model_id)
해당 토크나이저에 대한 정보는 허깅페이스 페이지의 모델 카드에서 확인할 수 있다. tokenizer.json 파일을 확인하면 해당 모델의 어휘 사전 정보를 볼 수 있다.

불러온 토크나이저에 예시 문장을 넣어보도록 하자.
tokenized = tokenizer("토크나이저는 텍스트를 토큰 단위로 나눈다")
print(tokenized)
{'input_ids': [0, 9157, 7461, 2190, 2259, 8509, 2138, 1793, 2855, 5385, 2200, 20950, 2],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
- input_ids : 입력 문장을 토큰화했을 때 각 토큰이 토크나이저의 어휘 사전의 몇 번째 항목인지를 나타냄
- token_type_ids : 이 값이 0이면 일반적으로 해당 문장이 첫 번째 문장임을 의미
- attention_mask : 이 값이 1이면 패딩이 아닌 실제 의미가 있는 토큰임을 의미
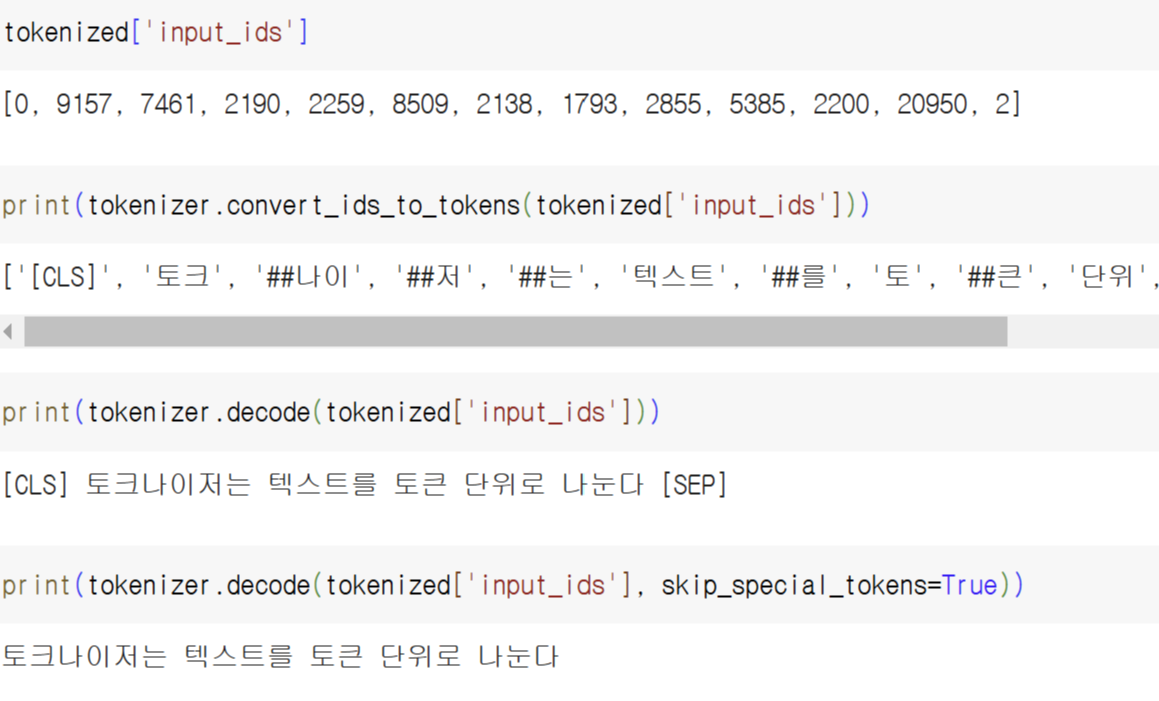
tokenizer.covert_ids_to_tokens에 tokenized['input_ids'] (어휘 사전에서의 인덱스)를 입력하면 해당 인덱스가 어느 문자에 해당하는지 보여준다. 위 출력 결과들에서 [CLS], [SEP]는 앞서 잠깐 언급했던 특수 토큰이다.
또한 해당 입력을 tokenizer.decode()에 입력하면 토큰을 다시 text로 되돌린 결과를 출력한다.
여러 문장을 토크나이저에 입력하기
tokenizer(['첫 번째 문장', '두 번째 문장'])
{'input_ids': [[0, 1656, 1141, 3135, 6265, 2], [0, 864, 1141, 3135, 6265, 2]],
'token_type_ids': [[0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1]]}
토크나이저에 두 개 이상의 text를 독립적으로 입력하기 위해서는 위와 같이 list 형태로 만들어 입력한다. (list 형태를 만들어주지 않거나, 아래처럼 list를 두 번 설정해주는 경우에는 각 문장이 서로 같이 입력되므로 주의해야 한다.)
만약 두 개의 문장을 tokenizer에 한 번에 입력하고 싶은 경우에는 위 상태에서 한번 더 list로 감싸준다.
tokenizer([['첫 번째 문장', '두 번째 문장']])
{'input_ids': [[0, 1656, 1141, 3135, 6265, 2, 864, 1141, 3135, 6265, 2]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
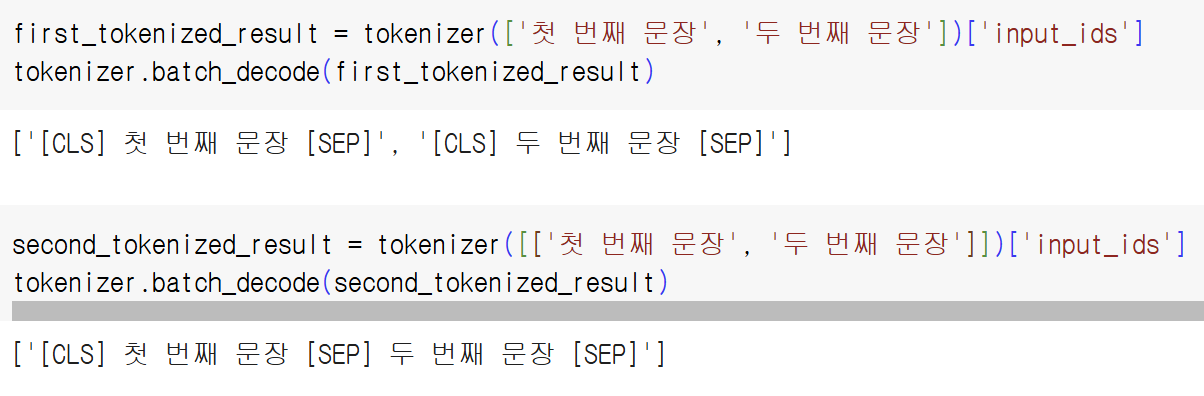
특수 토큰에 대해서 살펴보자.
- [CLS] : Classify token, First token 등으로 불리며 입력 문장을 토큰화 했을 때 가장 먼저 [CLS] 토큰으로 시작한다.
- [SEP] : Separate token으로, 두 개의 시퀀스를 분리하는 분기점 역할. 위 코드의 두 번째 예시에서, 두 개의 시퀀스가 한 번에 입력되었으므로 [SEP]를 통해 이를 나눠준 것.
tokenizer(['첫 번째 문장은 짧다.', '두 번째 문장은 첫 번째 문장보다 더 길다.'], padding='longest')
{'input_ids': [[0, 1656, 1141, 3135, 6265, 2073, 1599, 2062, 18, 2, 1, 1, 1, 1, 1, 1, 1], [0, 864, 1141, 3135, 6265, 2073, 1656, 1141, 3135, 6265, 2178, 2062, 831, 647, 2062, 18, 2]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
위처럼 tokenizer에 padding='longest'를 설정하면 입력한 문장 중 가장 긴 문장에 맞춰 패딩 토큰을 추가한다. 여기서는 두 번째 문장이 첫 번째 문장보다 더 길기 때문에, 길이를 맞춰주기 위하여 첫 번째 문장의 attention mask의 뒷 부분에 0이 추가된 것을 볼 수 있다.
학습 데이터셋 불러오기
from datasets import load_dataset
klue_mrc_dataset = load_dataset('klue', 'mrc')
위에서 불러온 LLM 모델은 바디만 pre-trained 되어있고, 헤더는 따로 가중치를 불러오지 않아 랜덤 초기화 된 상태였다. 그렇기에 유저가 직접 데이터셋을 이용하여 학습해주어야 하는데, 이번 실습에서는 huggingface에서 지원하는 dataset인 'klue'를 사용한다. 그 중에서도 'mrc' 데이터셋을 불러왔다.
만일 train 혹은 validation 중 하나만 불러오고 싶다면, load_dataset의 인자에 split='train' or 'validation'을 입력한다.
(허깅페이스의 데이터가 아닌, 유저 자체의 데이터셋을 사용하고 싶다면 load_dataset에 csv파일 등을 입력하면 된다.)
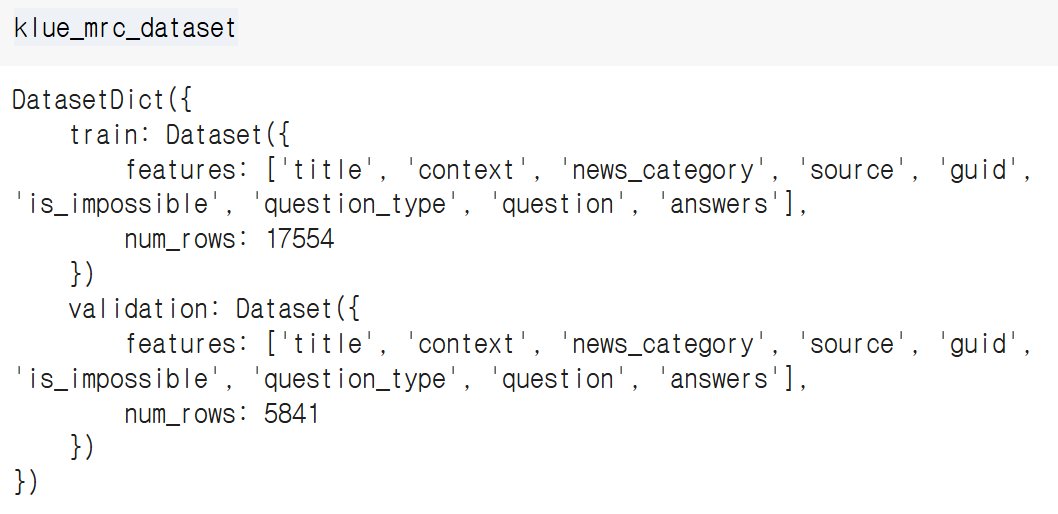
허깅페이스에서 불러온 데이터셋을 출력해보면 해당 데이터셋 dict가 어떤 형태로 저장되어있는지 보여준다. 여기서는 train 혹은 validation에 접근하여 title, context ... 등 찍어보면 어떤 형태로 데이터의 이름 / 맥락 등이 저장되어 있는지 볼 수 있다.
klue_tc_train = load_dataset('klue', 'ynat', split='train')
klue_tc_eval = load_dataset('klue', 'ynat', split='validation')
실제 학습에 사용할 데이터로 'klue'의 'ynat' 데이터를 불러온다. YNAT 데이터는 연합뉴스 기사의 제목(X)과 해당 기사가 어느 카테고리에 속하는지(Y)에 대한 정보가 담겨있다.

불러온 데이터에 features를 찍어보면, 위와 같이 데이터의 세부적인 정보를 확인할 수 있다. 위 정보로 미루어보아, 해당 데이터는 연합뉴스 기사의 제목들을 이용하여 IT과학 / 경제 / 사회 / 생활문화 / 세계 / 스포츠 / 정치 중 어떤 카테고리에 속하는 지 맞추는 모델을 생성하는 데 활용될 수 있음을 알 수 있다.
klue_tc_train = klue_tc_train.remove_columns(['guid', 'url', 'date'])
klue_tc_eval = klue_tc_eval.remove_columns(['guid', 'url', 'date'])
klue_tc_train
# Dataset({
# features: ['title', 'label'],
# num_rows: 45678
# })
url, date열은 다른 문제에서는 활용될 수 있겠지만, 해당 실습에서는 기사 제목(title)을 이용하여 카테고리(label)을 맞추는 모델을 생성할 것이므로 해당 두 열을 제외한 나머지는 삭제한다.
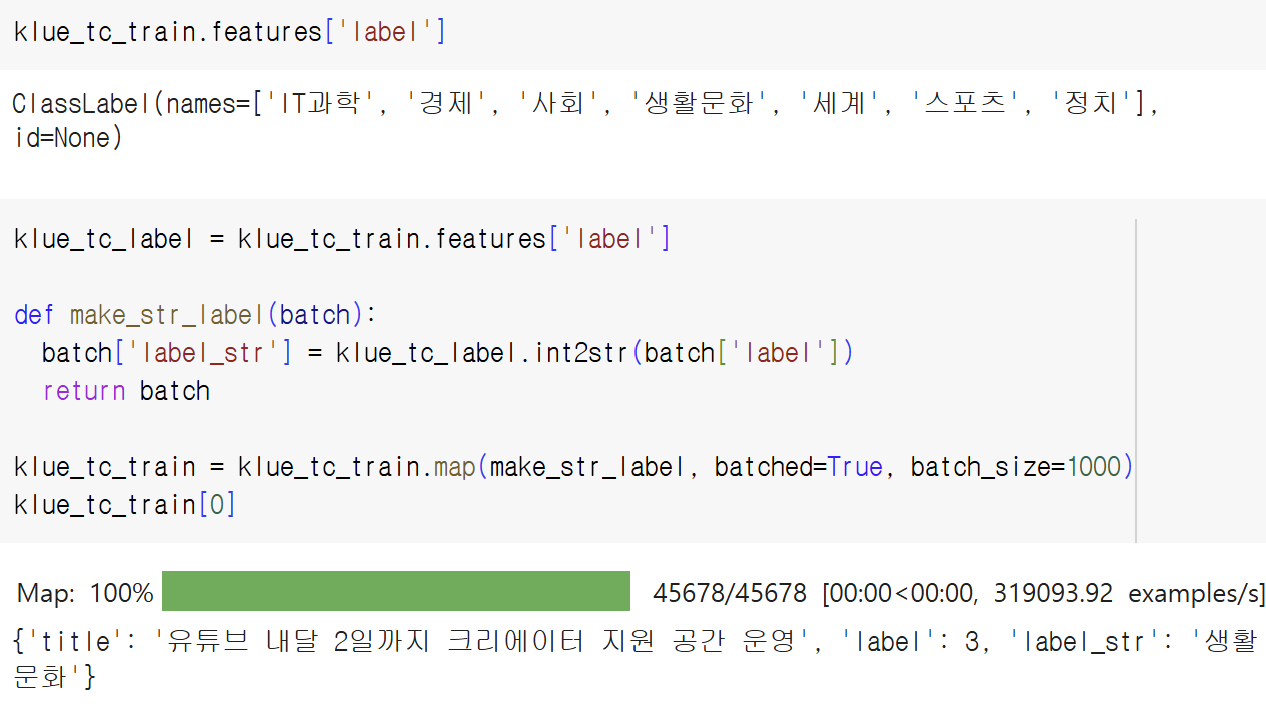
기존 데이터셋에는 label이 1,2,3,4 ... label ID 형태로 주어져있기 때문에, 이를 ClassLabel 객체에 담겨있는 카테고리명으로 매치시켜 label을 가시적으로 만들 수 있다.
또한 ClassLabel 객체에는 int2str 메서드가 숨겨져있는데, 이를 이용하여 label ID를 각각 매치되는 카테고리명으로 치환할 수 있다.
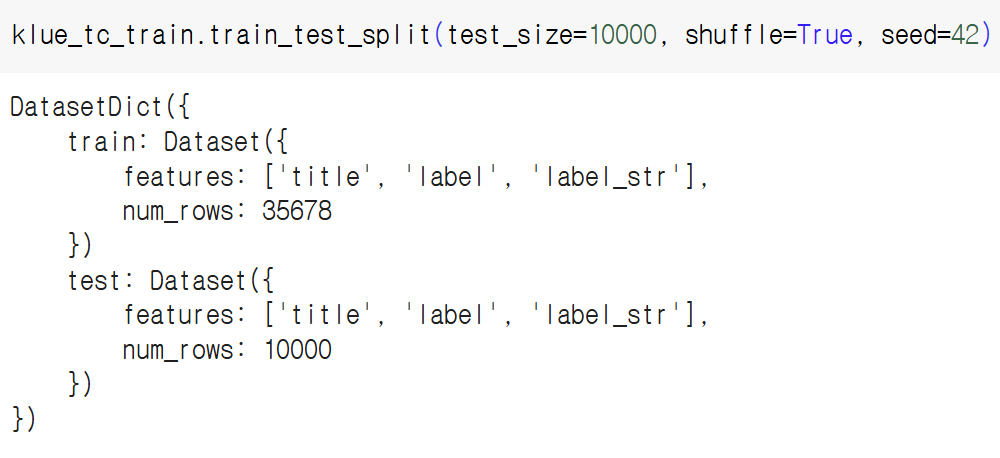
데이터 전체 (대략 4.5만개)를 사용하여 학습하면 시간이 너무 오래걸리므로, 10000개만 사용하기 위해 위 코드를 수행하여 test에 해당하는 부분만 학습에 사용한다. (train_size=10000으로 설정하고 train dataset을 사용해도 결과는 같다.)
train_dataset = klue_tc_train.train_test_split(test_size=10000, shuffle=True, seed=42)['test']
dataset = train_dataset.train_test_split(test_size=1000, shuffle=True, seed=42)
test_dataset = dataset['test']
valid_dataset = dataset['train'].train_test_split(test_size=1000, shuffle=True, seed=42)['test']
데이터셋 준비가 완료됐다면 허깅페이스의 Trainer API를 이용하여 손쉬운 학습을 진행할 수 있다.
허깅페이스에서 지원하는 Trainer API는 데이터셋 로드 / 모델 설정 / 모델 학습 과정을 몇 줄의 코드만으로 가능하게 해준다. 또한 compute_metrics 인자를 통해 평가 지표를 바꾸거나 콜백을 정의하여 특정 이벤트에서 모델 학습을 멈추는 등의 디테일 설정도 가능하다.
다만, LLM 모델을 학습하는 과정을 깊게 이해하는 데는 어려움이 있을 수 있다. (물론 이런 경우에는 다른 방식으로 학습을 진행하면 되므로 단점이라고 말하긴 어렵다. 취사선택)
import torch
import numpy as np
from transformers import (
Trainer,
TrainingArguments,
AutoModelForSequenceClassification,
AutoTokenizer
)
def tokenize_function(examples):
return tokenizer(examples['title'], padding = 'max_length', truncation=True)
model_id = 'klue/roberta-base'
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=len(train_dataset.features['label'].names))
tokenizer = AutoTokenizer.from_pretrained(model_id)
train_dataset = train_dataset.map(tokenize_function, batched=True)
valid_dataset = valid_dataset.map(tokenize_function, batched=True)
test_dataset = test_dataset.map(tokenize_function, batched=True)
transformers 라이브러리에서 불러오는 4가지 클래스
- Trainer : 모델 학습/평가를 관리하는 클래스
- TrainingArguments : 학습에 관련된 파라미터들을 지정하기 위한 클래스 (에포크, batch size, learning rate 등)
- AutoModelForSequenceClassification : 텍스트 분류 모델을 자동으로 load하는 클래스
- AutoTokenizer : 토크나이저를 load하는 클래스
tokenizer_function은 사용자가 불러온 tokenizer에 train/valid/test 데이터셋을 적용하는 용도이다. 해당 함수에서 padding = 'max_length'로 설정하여 입력된 title 문장의 최대 길이까지 padding한다.
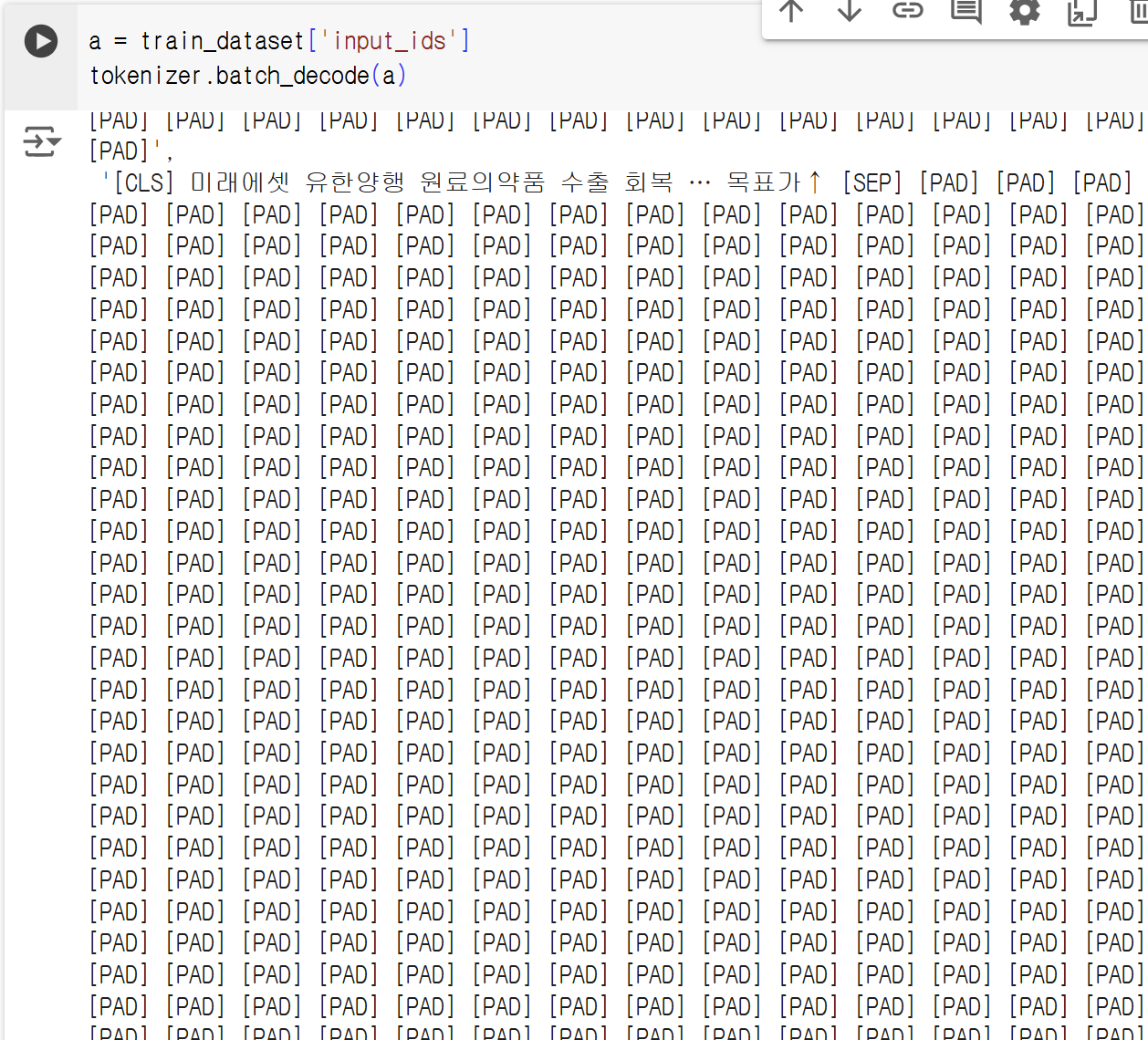
패딩이 어떻게 되었나 궁금해서 batch_decode 해보니 위와 같은 결과가 나왔다. 이게 맞나.....? 싶지만 일단 맞는걸로 하고 넘어가겠다.
training_args = TrainingArguments(
output_dir='/content/results',
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
evaluation_strategy='epoch',
save_strategy='epoch',
logging_dir='/content/logs',
learning_rate=5e-5,
weight_decay=0.01,
push_to_hub=False
)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy" : (predictions == labels).mean}
위에서 불러온 TrainingArguments 클래스를 이용하여 여거 파라미터를 설정해준다. compute_metrics 함수는 Trainer 클래스에 넣어줄 함수인데, 해당 클래스에 평가지표 metric을 넣어줘야 하기 때문에 미리 만들어주고 간다.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
trainer.evaluate(test_dataset)
이제 Trainer 클래스를 이용해 학습을 수행해본다. 위에서 설정한 모델/args/dataset 등을 전부 입력해주고, train() 메소드를 호출하여 학습을 진행한다. 정말 짧은 코드만으로 거대한 LLM 모델을 학습시킬 수 있다는 것이 Trainer 클래스의 가장 큰 장점이다.
참고로, klue/roberta-base 모델에 klue mrc 데이터셋 10000개만 사용해도 학습 시간이 굉장히 오래걸린다. (코랩 기준 GPU를 안쓰면 학습이 불가능하고, T4 GPU 사용시 1 epoch에 대략 13분 소요된다. 괜히 Large라는 형용사가 붙은 게 아니다. 또한, Trainer 클래스는 GPU 설정을 따로 입력해 줄 필요가 없고 현재 노트북 or 로컬환경에서 GPU 사용이 가능하다면 자동으로 GPU를 우선적으로 사용한다.)
# 테스트 데이터에서 첫 5개 데이터만 선택
sample_test_dataset = test_dataset.select(range(5))
# Trainer를 사용하여 예측 수행
predictions = trainer.predict(sample_test_dataset)
# logits 값에서 가장 높은 확률의 라벨을 예측
predicted_labels = np.argmax(predictions.predictions, axis=-1)
# 실제 라벨과 예측 라벨을 비교하여 출력
for i in range(5):
print(f"Text: {sample_test_dataset[i]['title']}")
print(f"Actual Label: {sample_test_dataset[i]['label']}")
print(f"Predicted Label: {predicted_labels[i]}\n")
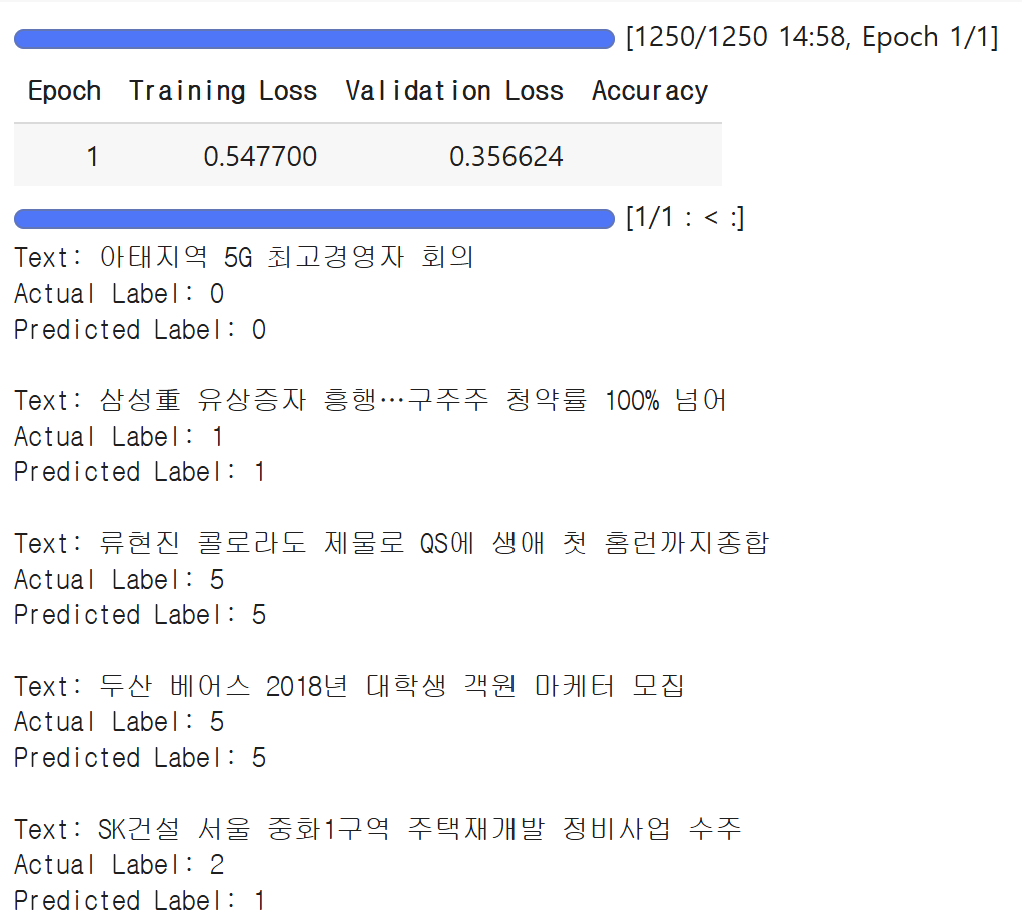
test dataset에서 5개만 뽑아서 prediction을 진행해보았다. 처음 4개는 맞췄지만, 마지막 데이터는 맞추지 못한 모습. 하지만 1에포크만 학습했다는 점을 감안하면, 아주 상당한 결과로 보인다.
Trainer를 사용하지 않고 학습
Trainer 클래스를 사용하면 어렵고 복잡해보이기만 하는 LLM 모델을 아주 쉽게 불러오고 학습할 수 있다. 하지만, 기존에 딥러닝 프레임워크를 이용해본 적 없다면 Trainer를 이용했을 때 과연 이것이 코드 측면에서 어떻게 동작하는 지 이해가 되지 않는다. 그렇기에 Pytorch를 이용한 학습을 진행해본다.
import torch
from tqdm.auto import tqdm
from torch.utils.data import DataLoader
from transformers import AdamW
def tokenize_function(examples):
return tokenizer(examples['title'], padding = 'max_length', truncation=True)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model_id = 'klue/roberta-base'
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=len(train_dataset.features['label'].names)).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_id)
def make_dataloader(dataset, batch_size, shuffle=True):
dataset = dataset.map(tokenize_function, batched=True).with_format("torch")
dataset = dataset.rename_column("label", "labels")
dataset = dataset.remove_columns(column_names=['title'])
return DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)
train_dataloader = make_dataloader(train_dataset, batch_size=8, shuffle=True)
valid_dataloader = make_dataloader(valid_dataset, batch_size=8, shuffle=False)
test_dataloader = make_dataloader(test_dataset, batch_size=8, shuffle=False)
파이토치로 데이터를 불러올 때는, DataLoader라는 클래스를 사용하여 데이터를 배치단위로 관리한다. Trainer API에서는 이 작업을 자동으로 해줬지만, 여기서는 직접 또 다른 클래스를 불러와줘야 한다.
def train_epoch(model, data_loader, optimizer):
model.train()
total_loss = 0
for batch in tqdm(data_loader):
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
total_loss += loss.item()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(data_loader)
return avg_loss
def evaluate(model, data_loader):
model.eval()
total_loss = 0
predictions = []
true_labels = []
with torch.no_grad():
for batch in tqdm(data_loader):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
logits = outputs.logits
loss = outputs.loss
total_loss += loss.item()
preds = torch.argmax(logits, dim = -1)
predictions.extend(preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
avg_loss = total_loss / len(data_loader)
accuracy = (np.array(predictions) == np.array(true_labels)).mean
return avg_loss, accuracy
num_epochs = 1
optimizer = AdamW(model.parameters(), lr=5e-5)
for epoch in range(num_epochs):
print(f"Epoch {epoch + 1}/{num_epochs}")
print('-' * 10)
train_loss = train_epoch(model, train_dataloader, optimizer)
print(f"Train Loss: {train_loss:.4f}")
valid_loss, valid_accuracy = evaluate(model, valid_dataloader)
print(f"Valid Loss: {valid_loss:.4f}")
print(f"Valid Accuracy: {valid_accuracy:.4f}")
_, test_accuracy = evaluate(model, test_dataloader)
print(f"Test Accuracy: {test_accuracy:.4f}")
모델 training / evaluation / test 과정을 담은 코드이다. Pytorch로 CNN / RNN 모델을 학습하는 과정과 전체 흐름이 아주 같다! 사실 허깅페이스 모델을 직접 학습해보고 싶었는데, 이 모델들이 Pytorch와 연동이 이렇게나 간편하다는 사실은 모르고 있었다. Pytorch를 기존에 다뤄본 경험이 있는 사용자에게는 허깅페이스 모델 학습도 전혀 무리가 없게끔 만들어 두었다. 자주 이용해야겠다 ~
'딥러닝' 카테고리의 다른 글
| [LLM] 4. 효율적인 GPU 사용, 분산 학습, LoRA, QLoRA (1) | 2025.01.28 |
|---|---|
| [LLM] 3. 좋은 데이터 셋, GPU (0) | 2024.11.03 |
| [LLM] 1. 임베딩, 어텐션, 트랜스포머 모델들 (1) | 2024.11.01 |
| 14. LSTM (Long Short Term Memory) 개념 + GRU (0) | 2023.11.15 |
| 13. RNN 코드실습 (0) | 2023.10.31 |



