컴퓨터는 텍스트를 그대로 계산에 사용할 수 없다.
그렇다면 어떻게 해야하는가 ..
텍스트를 적절한 단위로 자르고, 숫자로 변환하는 토큰화(tokenization) 과정이 필요하다.
input_text = "나는 최근 파리 여행을 다녀왔다"
input_text_list = input_text.split()
print("input_text_list: " , input_text_list)
str2idx = {word:idx for idx, word in enumerate(input_text_list)}
idx2str = {idx:word for idx, word in enumerate(input_text_list)}
print("str2idx: ", str2idx)
print("idx2str: ", idx2str)
input_ids = [str2idx[word] for word in input_text_list]
print("input_idx: ", input_ids)
# input_text_list: ['나는', '최근', '파리', '여행을', '다녀왔다']
# str2idx: {'나는': 0, '최근': 1, '파리': 2, '여행을': 3, '다녀왔다': 4}
# idx2str: {0: '나는', 1: '최근', 2: '파리', 3: '여행을', 4: '다녀왔다'}
# input_idx: [0, 1, 2, 3, 4]
토큰화 과정은 위처럼 진행될 수 있다.
여기서는 문장에서 발생한 공백을 기준으로 단어를 분리하여 순서대로 0~4까지 매핑하였다.
임베딩 (Embedding)
바로 위 토큰화 과정에서는 단어들을 토큰 ID로 매핑하여 토큰으로 만들어 주었다.
하지만 LLM 모델이 텍스트 데이터를 처리하기 위해서는 입력되는 토큰과 토큰 사이의 관계를 계산할 수 있어야 한다. 따라서 토큰을 N차원 벡터로 만들어주는 과정이 필요한데, 이것이 바로 임베딩이다.
import torch
import torch.nn as nn
embedding_dim = 16
embed_layer = nn.Embedding(len(str2idx), embedding_dim)
input_embeddings = embed_layer(torch.tensor(input_ids))
input_embeddings = input_embeddings.unsqueeze(0)
input_embeddings.shape
# torch.Size([1, 5, 16])
여기서는 임베딩 이후 벡터 차원을 16으로 설정하여 최종적으로 [1, 5, 16] size의 임베딩 결과를 얻었다.

input_embeddings를 출력해보면 제법 복잡한 형태로 임베딩 되었음을 확인할 수 있다.
하지만 임베딩 층의 역할이 '토큰에 의미를 부여하는 것'은 아니다. 임베딩 층은 단순히 토큰을 사용자가 원하는 크기의 차원의 벡터로 바꿔줄 뿐이다.
임베딩 층의 결과가 단어의 의미를 갖기 위해서는 LLM 모델이 학습 데이터로 충분히 훈련되어 있어야 한다. 즉, 어떤 모델의 임베딩 층이 적절히 학습된 이후에는 해당 임베딩 층을 사용했을 때 토큰이 단어의 의미를 갖는다. (학습이 잘 될수록 임베딩 층은 토큰(단어)에 담긴 의미를 더 잘 파악하게 된다.)
RNN과 트랜스포머의 가장 큰 차이점 : 입력의 순차적 처리
- RNN : 입력을 순차적으로 처리하기 때문에 입력데이터의 순서 정보가 고려됨.
- 트랜스포머 : 입력 순서에 상관없이 모든 입력을 동시에 처리함 → 순서정보가 사라지게 되는데, 텍스트에서 순서는 아주 중요한 정보이므로 인코딩을 통해 순서 정보를 추가한다.
Attention is All you need 논문에서는 사인/코사인을 이용해 순서(위치) 정보를 추가했다. 실제로 캐글 등 대회 코드를 보면 시계열이나 text 문제에 대해 사인/코사인을 이용하는 경우를 종종 볼 수 있다.
- 절대적 위치 인코딩(Absolute position encoding) : 수식을 통해 위치정보를 추가하는 방식(RNN)이나 임베딩으로 위치 정보를 학습하는 방식(Transformer) 모두 모델의 inference를 진행할 때는 이미 고정된 임베딩을 사용하기 때문에 절대적 위치 인코딩이라고 부른다.
- 비교적 구현이 간단하지만, 토큰 사이의 상대적인 위치 정보는 활용하지 못하며 긴 텍스트를 이용해 inference를 진행할 시에는 성능이 떨어진다는 단점 존재.
- 상대적 위치 인코딩(Relative position encoding) : 모든 입력 토큰을 동등하게 처리하여 입력으로 위치 정보를 함께 더해주는 방식.
embedding_dim = 16
max_position = 12
embed_layer = nn.Embedding(len(str2idx), embedding_dim)
position_embed_layer = nn.Embedding(max_position, embedding_dim)
position_ids = torch.arange(len(input_ids), dtype=torch.long).unsqueeze(0)
position_encodings = position_embed_layer(position_ids)
token_embeddings = embed_layer(torch.tensor(input_ids))
token_embeddings = token_embeddings.unsqueeze(0)
input_embeddings = token_embeddings + position_encodings
input_embeddings.shape
# torch.Size([1, 5, 16])
위 코드는 절대적 위치 인코딩 방법 中 위치 정보를 학습하는 방식을 나타낸다.
position_embed_layer라는 위치 임베딩을 위한 새로운 임베딩 층을 추가했다. 여기서 해당 임베딩 층의 입력 인자인 max_position, embedding_dim은 각각 입력 토큰의 최대 개수/임베딩 차원을 나타낸다.
최종적으로 token_embedding(기존 토큰 임베딩)과 position_encodings(토큰 위치 임베딩) 값을 더하여 최종 임베딩을 생성한다.
어텐션 (Attention)
어텐션은 기본적으로 사람이 문장을 읽을 때 특정 단어/부분에 집중하는 과정을 모방한 알고리즘이다. 어떠한 문장들이 입력되었을 때, 관련있거나 중요한 단어에 집중하는 알고리즘이 과연 어떻게 만들어지는 것일까?
먼저, 단어와 단어 사이의 관계를 계산한 결과에 따라 관련이 깊은지 or 낮은지를 판단해야 한다. 이후 관련이 깊은 단어는 맥락에 크게 반영하고, 그렇지 못한 단어는 적게 반영하는 과정이 필요하다.

어텐션 연산에서 사용되는 핵심 용어인 쿼리(query), 키(key), 값(value)에 대해 알아보자. (검색엔진을 예시로 들어 설명한다.)
- 쿼리(query) : 현재 처리중인 단어 또는 요소. 즉, 사용자가 입력한 단어를 의미
- 키(key) : 쿼리와 관련이 있는 문서를 찾기 위해 사용되는 문서의 특징을 key라고 한다. 즉, 각 문서마다 제목, 본문, 저자 등의 특징을 갖는데, 이 값들을 key로 사용하여 입력된 query와 얼마나 큰 연관을 갖는지 검색한다.
- 값 (value) : 쿼리와 관련이 높은 키들을 찾아 관련도 순으로 정렬하여 상위 N개를 사용자에게 전달한다고 해본다. 이때 전달된 문서들을 value라고 할 수 있다.
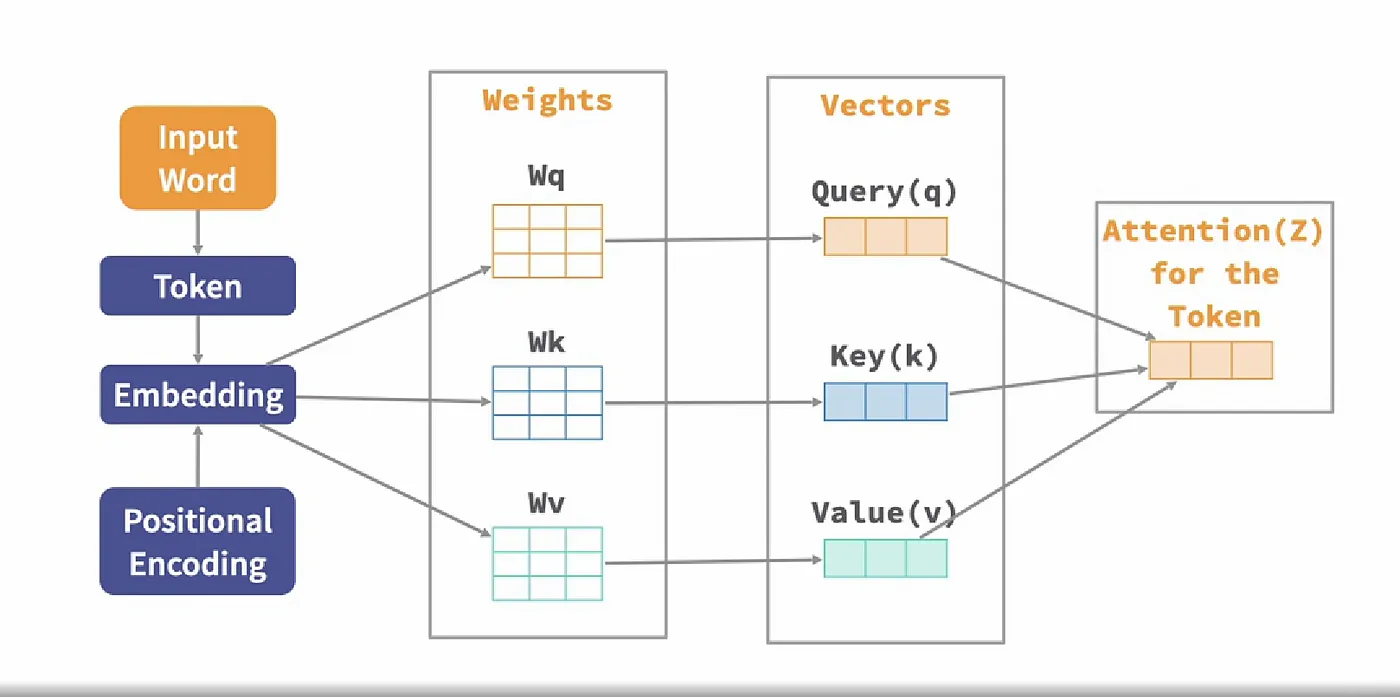
Key / Query / Value간 관계를 파악함에 있어 다음과 같은 예시를 들어본다.
- Key, Query 값들을 각각 임베딩한 후 각각 관계를 계산한다. → 이 경우, Key와 Query 값이 아예 같은 경우, 임베딩 값이 같기 때문에 관련도가 max에 달할 것이다. 'A'(query)라는 값을 입력했을 때 'A'(key)를 찾아준 것이니까 좋은 것 아닌가? 라는 생각을 할 수 있지만, 문서의 전체 맥락은 무시된 채 A라는 값이 포함되기만 하면 높은 관련도를 산출하는 것이므로 바람직하지 않다.
- 그래서 우리는 Query, Key에 대한 임베딩 가중치 W를 각각 적용하여 토큰과 토큰 사이의 관계를 계산하는 능력을 학습 대상으로 이용한다. (딥러닝 모델의 특정 기능을 심화하고 싶은 경우에는, 해당 기능에 weights를 넣어버리고 학습되게 하면 된다.)
이를 통해, Query / Key를 가중 임베딩 한 결과로 Value V1, V2, ... 일차원 벡터가 도출되는데 이를 바로 사용하는 것이 아니다. 각 단어들을 토큰 임베딩 한 값을 value Weight (Wv)로 변환한 value를 해당 결과에 가중합하여 최종 결과를 얻게 된다.
head_dim = 16
weight_q = nn.Linear(embedding_dim, head_dim)
weight_k = nn.Linear(embedding_dim, head_dim)
weight_v = nn.Linear(embedding_dim, head_dim)
query = weight_q(input_embeddings)
key = weight_k(input_embeddings)
value = weight_v(input_embeddings)
query.shape, key.shape, value.shape # 전부 torch.Size([1, 5, 16]))
Query, Key, Value의 파라미터는 전부 nn.Linear 선형 연산으로 수행된다.
위 코드에서 linear 연산을 거친 query, key, value는 각각 Weight 연산을 거친 이후의 값이므로, query와 key값의 관련도를 파악하고 / 그 과정에서 얻어진 attention 가중치를 위에서 얻은 values와 가중합하여 최종 결과를 얻는다.
이를 코드로 나타내면 다음과 같다.
from math import sqrt
import torch.nn.functional as F
def compute_attention(querys, keys, values, is_causal=False):
dim_k = query.size(-1) # 16
scores = querys @ keys.transpose(-2, -1) / sqrt(dim_k) # (1, 5, 16) @ (1, 16, 5) -> (1, 5, 5)
weights = F.softmax(scores, dim=-1) # softmax를 적용하여 점수를 정규화, 확률로 변환
return weights @ values # 어텐션 가중치를 values와 곱함
이때 wieghts 값을 출력해보면 예를 들어 [0.1143, 0.1571, 0.3279, 0.0557, 0.3450] ... 값을 가질 수 있는데, 입력된 5개의 토큰이 해당 차원에 대하여 얼마나 큰 관련을 갖는지를 확률로 보여준다.
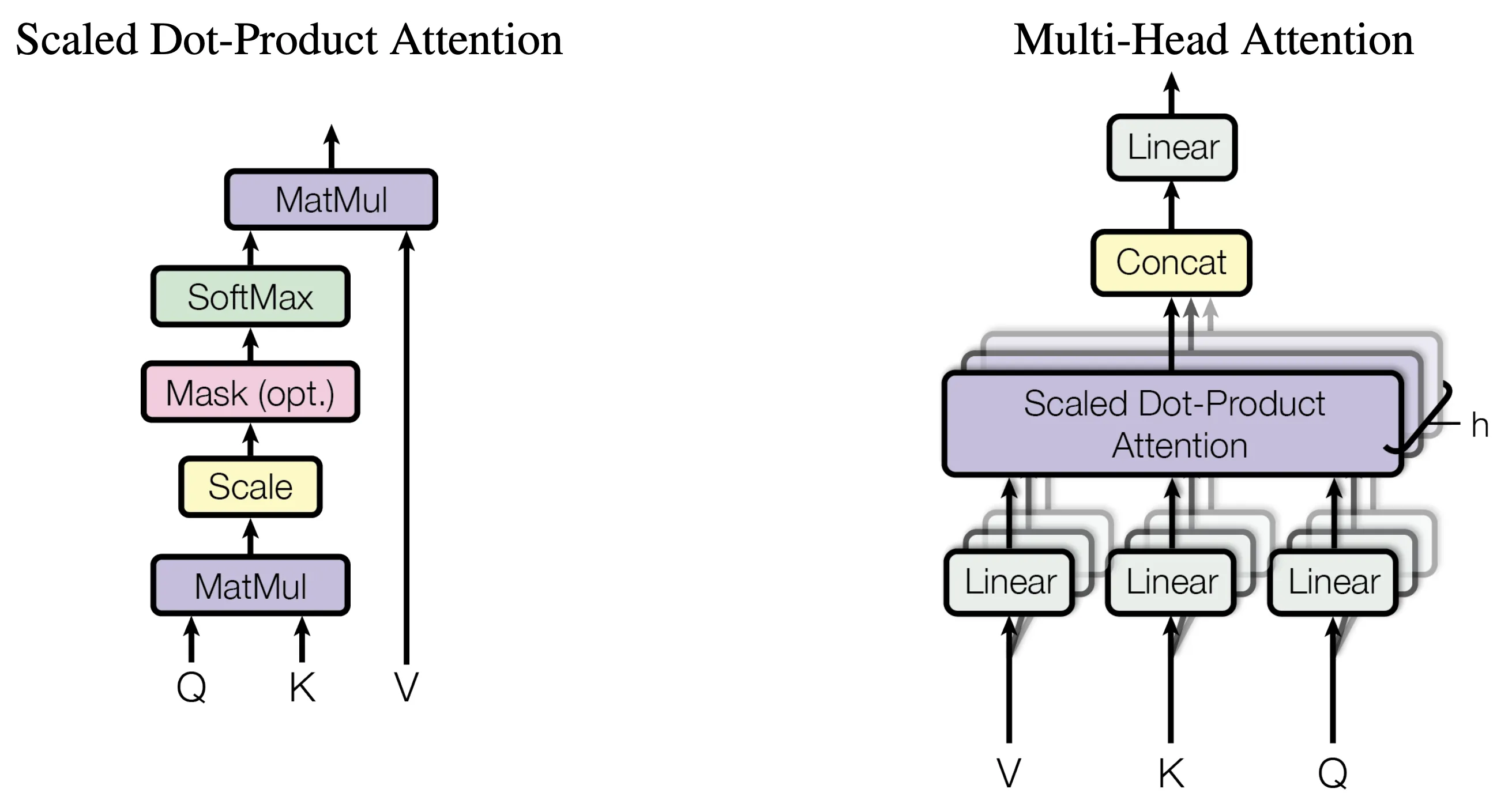
멀티 헤드 어텐션
바로 직전에 설명한 어텐션은 한 번에 하나의 어텐션 연산을 수행하는 싱글 헤드 어텐션 이었다.
하지만 여러 어텐션 연산을 사용하는 경우 성능을 더 높일 수 있다는 사실이 밝혀졌는데, 이러한 방법론을 멀티 헤드 어텐션이라고 부른다.
하나의 문제에 대하여 어텐션 연산을 동시에 여러 번 수행함으로써, 토큰 사이의 관계를 여러 측면에서 분석하는 것이다.
트랜스포머를 활용한 아키텍처
인코더 / 디코더 구조를 갖는 트랜스포머를 활용하여 최근 다양한 AI model이 등장하고 있다.
인코더와 디코더를 어떻게 활용하였는지에 따라 각 모델의 장단점에 대해 알아본다.
| 그룹 | 대표 모델 | 장점 | 단점 |
| 인코더 | BERT (Google) | 양방향 이해를 활용하여 디코더 모델에 비해 자연어 이해도가 높음. 입력에 대한 병렬 연산을 수행하여 빠른 학습과 추론이 가능. 다운스트림 성능이 뛰어남. |
자연어 생성에는 부적합한 형태이다. (아무래도 인코더만을 활용했기 때문에..) |
| 디코더 | GPT (Open AI) | 자연어 생성에 뛰어난 성능. 비교적 긴 context에 대해서도 성능이 우수함. |
단방향 이해를 수행하기 때문에 양방향 모델보다는 자연어 이해 성능이 낮다. |
| 인코더-디코더 | BART (Meta), T5 (Google) | 인코더-디코더 구조이기 때문에 생성/이해에 모두 뛰어난 성능을 보임. 자연어 이해 과정에서 양방향 방식을 사용하며, 인코더의 결과를 디코더에 활용할 수 있어 생성 능력 또한 우수함. |
인코더와 디코더를 모두 사용하기 때문에 아키텍처가 매우 복잡함. 학습에 더 많은 데이터 / 컴퓨팅 자원이 소모됨. |
1. BERT (Bidirectional Encoder Representations from Transformers)
- Bidirectional : 양방향 문맥을 모두 활용하여 텍스트를 이해한다는 특성 덕에 자연어 이해 성능이 좋다. 이러한 장점으로 BERT가 성공을 거두고, 차후 RoBERTa, ELECTRA 등 여러 인코더 기반 모델들이 등장하였다.
- 입력 token의 일부를 mask token으로 대체하고, mask token을 맞추는 MLM(Masked Language Modeling)을 수행하여 사전 학습된다.
- MLM 방식으로 사전학습 된 모델은 차후에 적용되는 과제에 따라 fine tuning되어 사용된다.
- Text classification 뿐만 아니라, token classification, question answering, natural language inferece 등 자연어 이해 작업에 성능이 좋다.
2. GPT (Generative Pretrained Transformer)
- Generative : 생성 작업을 위해 만들어진 모델이며, 해당 목적에 걸맞게 트랜스포머 아키텍처 중 디코더만을 활용한 모델이다.
- 디코더를 이용한 생성 작업은 인코더와는 달리 입력 토큰이과 이전에 생성된 토크만을 활용하기 때문에 단방향 방식이다.
- GPT는 다음 토큰을 예측하는 방식으로 사전 학습을 수행한다.
3. BART (Bidirectional and Auto Regressive Transformer), T5 (Text To Text Transfer Transformer)
- 트랜스포머 원 논문처럼 인코더/디코더를 모두 활용한 모델이다.
- BART는 메타에서 개발되었으며 BERT(인코더), GPT(디코더)의 장점을 결합한 모델이다.
- 모태가 되는 트랜스포머 모델과 유사한 형태를 가지면서, 인코더 부분에서 양방향 추론이 가능하다는 점이 BART의 특징.
- T5는 구글에서 개발되었으며 입력의 시작(prefix)에 과제 종류를 지정하여 작업 종류에 따라 다양한 동작을 하도록 학습시켰다는 특징이 있다. 예를 들어, '영어를 한글로 번역'이라는 prefix를 제공하여 모델이 어떤 작업을 수행해야 하는 지 사용자가 알려주는 형태이다.
'딥러닝' 카테고리의 다른 글
| [LLM] 3. 좋은 데이터 셋, GPU (0) | 2024.11.03 |
|---|---|
| [LLM] 2. 허깅페이스 트랜스포머 모델 학습하기 (0) | 2024.11.01 |
| 14. LSTM (Long Short Term Memory) 개념 + GRU (3) | 2023.11.15 |
| 13. RNN 코드실습 (0) | 2023.10.31 |
| 12. RNN (Recurrent Neural Network) 이론 (0) | 2023.10.06 |



