이 포스트는 Do it 딥러닝 교과서 (윤성진 저)를 참고하여 만들어졌음!
신경망 모델을 학습할 때 loss function의 최적해와 가까운 곳에서 학습을 시작하면 빠르게 최적해를 찾을 수 있다. loss function의 차원은 신경망 모델의 parameter 개수와 같다. (신경망 모델의 parameter 전부를 거쳐서 나온 output과 target을 비교하여 loss를 계산하므로) 따라서 loss function을 간략하게 도식화 하는 것 조차 불가능한 와중에 어느 지점이 최적해와 가까운지 어림잡는 것은 불가능해 보인다.
weights의 학습 시작지점에 따라 모델의 성능이 크게 변동될 수 있기 때문에 초기화를 잘 해주는 것 역시 중요하다.
상수 초기화
가중치를 전부 0으로 초기화

이때 hidden layer 뉴런
activation function이 ReLU 혹은 hyperbolic tangent이면 출력은 항상 0이며 sigmoid이면 항상 0.5이다. 역전파를 위해 맨 첫 계층
이때
가중치를 전부 0이 아닌 상수로 초기화
이 경우 weights 값이 0이 아니므로 학습은 가능하다. (
가우시안 분포 초기화
따라서 weights들은 서로 다른 0이 아닌 값으로 초기화되어야 한다. 이를 위해 gaussian distribution을 따르는 난수를 이용하여 초기화 할 수 있다. 10개의 layer를 가지며 activation으로 hyperbolic tangent를 사용하는 딥러닝 신경망 모델을 예시로 들어본다.
가중치를
위 그림은 가중치를 아주 작은 수로 초기화 한 경우 각 layer들의 output 분포를 나타낸 것이다.
가중치를
weights를 너무 크게 초기화 한 경우 layer를 거치면서 output은 위와 같이 나타난다. 값들이 -1과 1로 수렴하는 이유는 activation으로 hyperbolic tangent를 사용하였기 때문이다. 즉 뉴런의 출력인
위까지는 망한 초기화의 예시이다. 가중치 초기화를 너무 크거나 너무 작게하면 학습에 지장이 생긴다. 우리는 입력 데이터가 layer를 통과하더라도 데이터의 크기가 유지되는 가중치를 사용해야 한다. 어떤 방법이 있을까?
Xavier Initialization
Xavier 초기화는 activation으로 sigmoid 계열을 사용할 때 채택하는 가중치 초기화 방법이다. Input data의 분산이 output에서 유지되도록 하여 데이터가 layer를 거쳐도 같은 크기로 유지되게 한다.
Xavier Initialization을 유도하기 위한 몇 가지 가정이 존재한다.
- Activation은 선형이다.
- Sigmoid를 사용하는 경우 입력 데이터가 0 근처의 값이라면 선형으로 근사할 수 있다.
- 따라서 activation의 입력값의 절댓값이 굉장히 작다고 가정한다.
- Input data와 weights는 다음 성질을 만족한다.
- Input data
- Input data의 각 차원
- weights의 각 차원
- 각
- Input data
이제 Xavier 초기화 식을 유도한다. 먼저 activation이 linear라고 가정했으므로 activation의 출력
위 식의 양변의 variance를 구하면 다음과 같다.
여기서
이때 각
Xavier 초기화의 목적은 뉴런의 입력과 출력의 variance를 같게 만드는 것이었으므로
따라서 Xavier 초기화는 weights의 variance
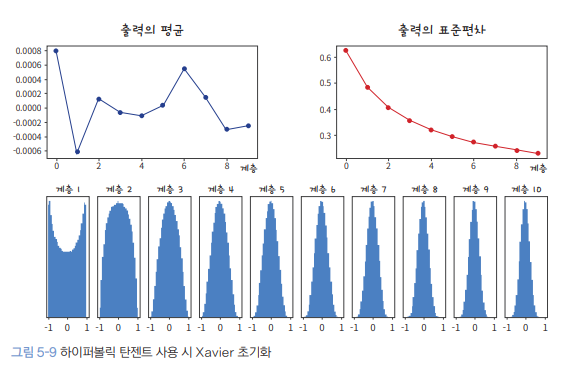
He Initialization
Sigmoid 계열 (ex hyperbolic tangent) activation을 사용할 때는 Xavier 초기화가 잘 동작한다. 하지만 ReLU를 사용하는 경우에는 input이 음수일 때 input이 0으로 변하여 출력되므로 activation이 선형이라는 가정을 할 수 없다. 예를들어 ReLU를 사용했을 때 input의 50% 가량이 0으로 출력된다면 input data의 variance (input data의 크기)는 절반으로 줄어든다. (input과 output의 variance가 유지되지 못한다는 것이다.)
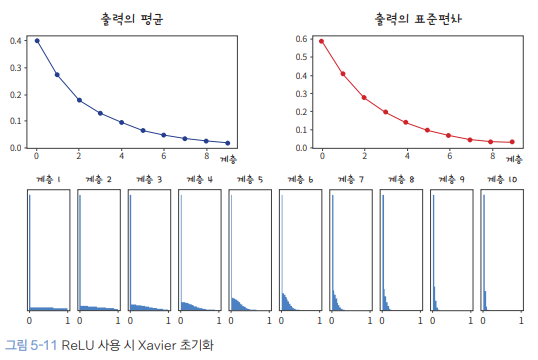
실제로 ReLU에 입력되는 input 중 절반이나 음수인 경우는 잘 없겠지만 (진짜 그런가?) 중요한 점은 ReLU에 음수가 입력되는 경우 그것들을 전부 0으로 만들어버리므로 ReLU를 거칠수록 데이터의 분산이 작아진다는 것이다.
위 그림은 activation으로 ReLU를 사용할 때 Xavier Initialization을 사용한 결과이다. 매 layer를 거칠 때마다 data의 분산이 작아져서 input과 output의 variance가 달라지는 문제점이 발생한다.
이를 개선하기 위한 것이 바로 He Initialization이다. He는 ReLU를 사용했을 때 뉴런의 input과 output의 variance를 같게 유지해준다. ReLU 특성 상 negative input이 입력되면 전부 0으로 만드는 특성 때문에 variance가 절반으로 감소한다. 절반으로 줄어드는 variance를 weights에 미리 보상하는 느낌으로 다음과 같이 초기화를 해준다.
Xavier 초기화에서 사용했던 weights variance에 2를 곱한 형태로 나타난다. ReLU를 사용하며 절반 감소한 variance를 weights를 통해 다시 복구시켜주는 것이다.
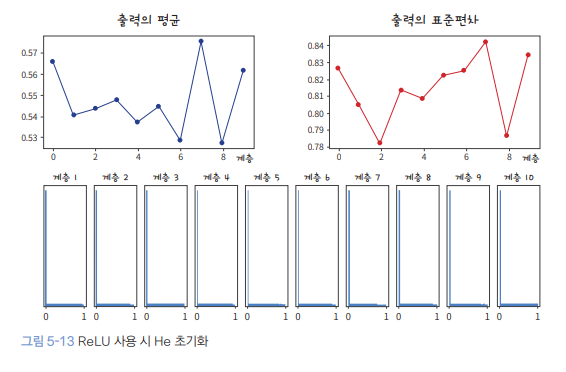
ReLU activation을 사용할 때 He Initialization을 적용한 결과이다. output 값들 중 0의 비율이 압도적으로 높은 이유는 negative input은 전부 0으로 만들어버리는 ReLU의 특성 때문이다. 출력 표준편차가 layer를 여러 번 거쳐도 0으로 죽지 않는다는 것을 확인할 수 있다.
'딥러닝' 카테고리의 다른 글
| VGG net 논문리뷰 + 실습 (0) | 2023.10.04 |
|---|---|
| 11. 컨볼루션 신경망, CNN (Convolution neural network) (0) | 2023.09.27 |
| 8. 최적화 Optimization (0) | 2023.09.20 |
| 7. 손실함수 Loss function (0) | 2023.09.15 |
| 6. 배치, 미니배치, SGD (0) | 2023.09.15 |


