VGG net
이 포스팅에서는 CNN을 공부해봤다면 반드시 한 번쯤은 써봤을 법한 모델 VGG 논문을 리뷰해보도록 한다.
논문 발표시점은 2014년으로 ImageNet의 이미지 분류대회 ILSVRC가 활발히 진행되던 시점이라 해당 대회의 이야기가 논문 스토리텔링의 중추가 되었다. (ILSVRC은 2010년 부터 2017년까지 매년 개최되었다.)
Introduction은 가볍게 건너뛰고 해당 논문에서 제시하는 Convnet (convolutional network)의 구조와 몇가지 설정사항을 확인해보도록 한다.
- Input image size는 224x224x3 (RGB channel)으로 고정한다.
- (very small receptive field를 가지는) 3x3 filter를 사용한다. (3x3 filter는 상하좌우 + center를 포함하는 조건에서 가장 작은 size의 filter이다.)
- 1x1 filter도 사용했다.
- convolution stride는 1로 고정하며, 모든 3x3 conv에 대해 padding=1이 추가된다.
- 간간히 2x2 size, stride=2의 maxpooling layer를 넣어주었다.
- conv층을 여럿 쌓은 후 Fully-connected 층으로 진행된다. (4096 -> num of class -> softmax)
Architecture

VGG는 11개 부터 19개 층을 갖는 모델까지 총 6개로 구분된다. 두 번째 열의 LRN은 Local Response Normalization을 의미한다. LRN layer는 feature map의 특정 각 위치에서 가장 큰 값을 1으로 바꾸고 나머지 값은 정규화한다.
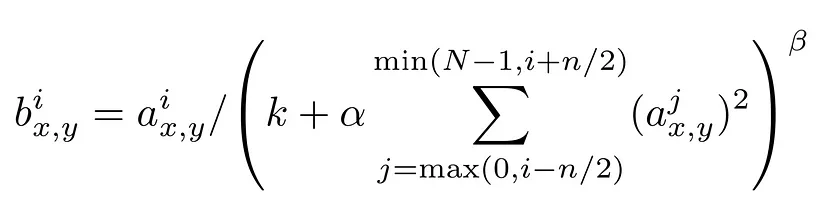
LRN을 이용하면 feature map의 분산을 줄이고 입력 이미지의 공간적인 변화에 더 강건한 CNN 모델을 만들 수 있다고 한다. 하지만 최근에는 LRN 대신 Batch Normalization 등의 정규화 방법이 선호된다.
이전 CNN 모델들과 비교했을 때 VGG net의 특이점은 3x3 conv filter만 고집하여 사용한다는 것이다. 3x3 filter를 두 층 쌓으면 5x5 filter와 동일한 receptive field를, 세 층 쌓으면 7x7 filter와 동일한 receptive field를 얻을 수 있다.
3x3 filter를 세 층 사용하는 것 보다 7x7 filter를 한 번 사용하는 것이 더 간편해 보이는데 왜 3x3를 고집할까?
$\rightarrow$ 3x3 filter를 겹쳐 사용하는 것이 파라미터 개수를 대폭 줄일 수 있다.
- 3x3 filter를 3번 사용하는 경우 파라미터 수 $\rightarrow$ $27C^2$ (이때 $C$= channel)
- 7x7 filter를 1번 사용하는 경우 파라미터 수 $\rightarrow$ $49C^2$
따라서, 어차피 동일한 receptive field를 가진다면 3x3 filter를 여러 번 사용하는 것이 더 낫다. (한 layer를 거치며 ReLU 등의 non-linearity를 추가할 수 있으므로 더 자세한 표현이 가능한 것은 덤이다.)
1x1 convolution?
위 구조도의 Model C에서 conv1 layer가 포함된 것을 확인할 수 있다. 심지어 이 conv1층은 직전 conv layer와 channel 개수도 같으므로 image size, channel을 전부 유지하는 linear operation같아 보인다. 하지만 conv1을 거친 후 non-linearty (ReLU 등)을 거치므로 이는 곧 image size를 유지하며 비선형성을 추가하는 과정으로 해석할 수 있다.
사실 이처럼 작은 사이즈 (3x3)의 filter를 사용하는 기법은 2011년 Ciresan에 의해 먼저 제안되었지만, 기존 방식은 VGG보다 layer가 깊지 않았고, ILSVRC에서 측정되지 않았다는 점에서 차이를 갖는다.
또한, ILSVRC-2014에서 최고의 성능을 보여준 CNN 모델은 GoogLeNet이었다. GoogLeNet은 크기가 작은 conv filter (3x3, 1x1, 5x5)를 사용하여 깊은 층을 쌓았다는 점에서 VGG와 다소 비슷하지만, 그 구조가 VGG보다 복잡하고 첫 번째 층에서 연산량을 감소시키기 위해 spatial resolution을 크게 저하한다는 단점을 갖는다.
VGG 16 CNN 모델 만들기
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision.transforms as T
from torchvision.datasets.cifar import CIFAR10
from torchvision.transforms import Compose
from torchvision.transforms import RandomHorizontalFlip, RandomCrop, Normalize
from torchvision.transforms import ToTensor
from torch.utils.data.dataloader import DataLoader
from torch.optim.adam import Adam간단한 실습을 위해 CIFAR10 이미지를 사용하였다.
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_con):
super(BasicBlock, self).__init__()
if num_con == 2:
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
elif num_con == 3:
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2) # = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
if hasattr(self, 'conv3'):
x = self.conv2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.relu(x)
else:
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
return x
위 구조도에서 D번째 열에 있는 16 weight layers를 구현해보았다. 상위 2개 conv block은 filter를 두 layer 거치는 반면, 하위 3개 conv block은 conv filter를 세 개 layer 거치기 때문에 이 두 경우를 구분할 수 있도록 구성하였다.
한 Block 내에 num_con 개수 만큼의 convolution filter가 들어가는 구조이다.
class VGG16(nn.Module):
def __init__(self, num_classes):
super(VGG16, self).__init__()
self.block1 = BasicBlock(in_channels=3, out_channels=64, num_con=2)
self.block2 = BasicBlock(in_channels=64, out_channels=128, num_con=2)
self.block3 = BasicBlock(in_channels=128, out_channels=256, num_con=3)
self.block4 = BasicBlock(in_channels=256, out_channels=512, num_con=3)
self.block5 = BasicBlock(in_channels=512, out_channels=512, num_con=3)
self.fc1 = 0 # forward 함수에서 정의
self.fc2 = nn.Linear(in_features=4096, out_features=4096)
self.fc3 = nn.Linear(in_features=4096, out_features=num_classes)
self.relu = nn.ReLU()
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = torch.flatten(x, start_dim=1)
in_features = x.size(1)
self.fc1 = nn.Linear(in_features=in_features, out_features=4096).to(device)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
fc1의 입력은 block5의 출력을 flatten한 1차원 벡터의 길이가 되어야 하는데 이 값이 input image size에 의존하여 가변하는 값이다. (224x224에 맞춰서 7*7*512로 고정해둔다면 다음번에 이미지 크기를 바꾸는 순간 오류가 발생한다.)
따라서 forward에서 flatten 된 벡터의 길이를 x.size(1)으로 구하고, 이를 fc1의 입력으로 사용하도록 했다.
__init__에서 설정한 layer들은 모델 클래스에 model.to(device)가 수행되면 해당 device(gpu)로 바로 넘어가지만 forward 함수는 모델 클래스를 정의했을 때 실행되는 함수가 아니므로 여전히 cpu에 남아있다. 따라서 forward에서 정의한 fc1에 to.(device)를 붙여준다.
transforms = Compose([
RandomCrop((32, 32), padding=4),
RandomHorizontalFlip(p=0.5),
ToTensor(),
Normalize(mean=(0.4914, 0.4822, 0.4465), std=(0.247, 0.243, 0.261))
])낭낭하게 transform을 정의해준다.
training_data = CIFAR10(root='./', train=True, download=True, transform=transforms)
test_data = CIFAR10(root='./', train=False, download=True, transform=transforms)
train_loader = DataLoader(training_data, batch_size=32, shuffle=True)
test_loader = DataLoader(test_data, batch_size=32, shuffle=False)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = VGG16(num_classes=10)
model.to(device)CIFAR10 dataset을 불러오고 이를 data loader에 담아준다. 위에서 정의한 VGG model도 호출
lr = 1e-3
optim = Adam(model.parameters(), lr=lr)
for epoch in range(100):
for data, label in train_loader:
optim.zero_grad()
preds = model(data.to(device))
loss = nn.CrossEntropyLoss()(preds, label.to(device))
loss.backward()
optim.step()
if epoch==0 or epoch%10 == 9:
print(f"epoch{epoch+1} loss:{loss.item()}")
torch.save(model.state_dict(), '/content/CIFAR.pth')학습 곡올윙. 생각보다 학습시간이 너무 오래걸려서 결과보는건 포기했다.
num_corr = 0
with torch.no_grad():
for data, label in test_loader:
output = model(data.to(device))
preds = output.data.max(1)[1]
corr = preds.eq(label.to(device).data).sum().item()
num_corr += corr
print(f"Accuracy:{num_corr/len(test_data)}")
'딥러닝' 카테고리의 다른 글
| 13. RNN 코드실습 (0) | 2023.10.31 |
|---|---|
| 12. RNN (Recurrent Neural Network) 이론 (0) | 2023.10.06 |
| 11. 컨볼루션 신경망, CNN (Convolution neural network) (0) | 2023.09.27 |
| 9. 초기화 Initialization (0) | 2023.09.21 |
| 8. 최적화 Optimization (0) | 2023.09.20 |



