내가 작년 동아리에 가입할 당시 회장님이 군집화를 통해 팀원을 짰었다. 이번 학기 신입부원 팀을 어떻게 짤지 고민하다가 작년 회장님이 당시 사용했던 설문지를 공유해주셔서 (ㄳ ㅎㅎ) 그 방법론을 사용하여 군집화 실습을 해보기로 했다.
큰 틀은 그대로 가져가되 약간의 베리에이션을 추가하고 싶어서 설문지의 질문을 다수 교체했고, K means에 더하여 계층 군집화도 사용해 봤다.

라이브러리 불러오기
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA!pip install Faker
from faker import Faker
import random
설문지 데이터 불러오기
df = pd.read_csv('...', encoding='utf-8')
df = df.iloc[:, 1:]
df.columns = [df.columns[0]] + ['q' + str(i) for i in range(1, len(df.columns))]
df.rename(columns={df.columns[0]: '이름'}, inplace=True)
fake = Faker()
def generate_random_name():
return fake.first_name()
df['이름'] = [generate_random_name() for _ in range(len(df))]
df
블로그에 올리려면 회원분들 이름을 가명으로 대체해야 했다. 좋은 방법이 없을까 싶어서 GPT한테 물어봤는데, Faker라는 툴을 알려줬다. 위 코드는 Faker 인스턴스를 사용하여 '이름' 열을 전부 랜덤한 영어 이름으로 바꾼 결과이다.
K means
먼저 군집화를 여러 개 사용해보고 싶었던 나는 다음과 같은 방법을 사용했다.
0. 목표 군집 개수는 총 5개이다.
1. K means로 전체 데이터(20개)를 2개의 군집으로 나눈다.
2. 계층적 군집화로 각 2개 군집을 다시 2 or 3개 군집으로 분할한다.
X = df.iloc[:, 1:] # '이름' 열은 정보가 아니므로 제외한다.
n_clusters = 2
kmeans = KMeans(n_clusters=n_clusters, random_state=46)
kmeans.fit(X)
df['Cluster'] = kmeans.labels_grouped = df.groupby('Cluster')
for cluster, group in grouped:
names = group['이름'].tolist()
print(f"Cluster {cluster}: {names}")K means를 사용하여 두 개의 군집으로 분할한 결과는 위와 같다. Cluster 0에는 12개, Cluster 1에는 8개 데이터 포인트가 할당되었으므로 이들을 다시 3개, 2개 군집으로 분할하면 총 5개 팀을 얻는다.
이제 위 클러스터링 결과를 시각화 해보자.
from mpl_toolkits.mplot3d import Axes3D
pca = PCA(n_components=3)
pca.fit(X)
x_pca = pca.transform(X)
x_pca
pca_df = pd.DataFrame(x_pca)
pca_df['cluster'] = df['Cluster']데이터 포인터들을 3차원 평면에 시각화하기 위해 components=3으로 설정하여 PCA를 수행했다. 시각화 하고싶은 평면의 차원에 맞춰 PCA에서 남길 columns 개수를 적절히 설정하면 된다.
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(pca_df.iloc[:, 0], pca_df.iloc[:, 1], pca_df.iloc[:, 2], c=pca_df['cluster'])
ax.set_xlabel('Component 1')
ax.set_ylabel('Component 2')
ax.set_zlabel('Component 3')
plt.show()K means 클러스터링 시각화 결과는 위와 같다. 노랑, 진보라, 걍 보라 3개 색으로 표현되었다.
K means를 적용한 원본 데이터는 11차원이지만 이를 PCA를 통해 3차원으로 압축한 후 시각화 하였기 때문에 위 그래프가 데이터들의 정확한 관계를 표현한다고 볼 수는 없다. 대략적인 관계를 해석하는 용도로만 사용하면 된다.
Hierarchy clustering
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
df1 = df[df['Cluster'] == 1]
df2 = df[df['Cluster'] == 0]
df1 = df1.reset_index(drop=True)
df1 = df1.drop(columns=['Cluster'])
df2 = df2.reset_index(drop=True)
df2 = df2.drop(columns=['Cluster'])먼저 K means 결과를 기준으로 cluster 0,1에 해당하는 데이터들을 각각 df1, df2로 따로 저장하였다.
linkage_matrix = linkage(df1.iloc[:, 1:], method='ward')
cluster_labels = fcluster(linkage_matrix, t=14.5, criterion='distance')
dendrogram(linkage_matrix)
plt.title('Hierarchical clustering Dendrogram')
plt.xlabel('Sample Index')
plt.ylabel('Distance')
plt.show()
잠깐! 계층적 군집화란? 가장 거리가 가까운 두 군집을 하나로 통합하면서 점점 군집의 개수를 줄여나가는 방식이다.
위는 K means로 얻은 첫 번째 군집에 대하여 계층적 군집화를 적용한 후의 Dendrogram(덴드로그램)이다.
여기서 Dendrogram이란, Hierarchical Clustering 결과 분석에 사용되며 데이터들의 관계를 위처럼 트리 구조로 표현한다. 중요한 점은 Dendrogram은 데이터 포인트 간 관계를 나타내는 용도로만 사용될 뿐, 그래프들의 색이 군집을 의미하는 것은 아니다. (Dendrogram을 보고 사용자가 직접 군집을 나눌 경계를 선택한다.)
위 Dendrogram을 약간 해석해보면 다음과 같다. 먼저 sample1, 2는 약 10정도의 distance를 가지고 이들을 한 군집으로 생각할 수 있다. 그리고 이 군집의 중심과 sample3은 약 12만큼의 distance를 가진다.
또한 위 코드에서 t값은 threshold를 의미하는데, 데이터 포인트들 간 distance가 t값을 넘지 않으면 하나의 군집으로 묶이게 된다. 이때 위 Dendrogram을 사용하면 클러스터 개수를 마음대로 설정할 수 있다. (계층적 군집화의 큰 장점)
위 그래프를 보면 distance 14~16 구간에서 군집이 2개로 분할된다. 따라서 threshold를 14~16 구간에 설정하면 2개의 cluster를 얻을 수 있다. 예를들어 5개의 군집을 얻고싶다면 t=11로 설정하면 된다.

하여튼 2개 군집으로 나눈 결과는 다음과 같다.
df1['Cluster'] = cluster_labels
grouped = df1.groupby('Cluster')
for cluster, group in grouped:
names = group['이름'].tolist()
print(f"team {cluster}: {names}")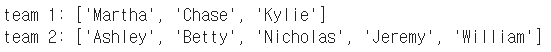
이제 K means에서 두 번째 그룹으로 나뉘었던 군집에 계층적 군집화를 적용해본다. 방식은 위와 완벽히 동일하다.

진짜 아득해지는 덴드로그램을 얻었다. 어떻게 잘라도 오른쪽 보라색 부분에 사람이 너무 몰려있다.
망했음을 직감하고 계층적 군집화를 포기했다 ~ ㅎㅎ. 하지만? K means만 쓰던 나에게 새로운 기법을 경험하게 해준 좋은 경험이다.
위에서 사용한 K means -> 계층적 군집화 방식이 망했으므로, 그냥 K means로 5개 군집을 나누기로 했다. 그 결과는 다음과 같다.


마지막 팀에 한 명만 할당된 게 아쉽긴 하지만 그 외 모든팀은 4~5 명이 할당되었기 때문에 이 결과를 참조하여 인원을 적절히 배분했다.
끝~
'딥러닝' 카테고리의 다른 글
| 2. 분류와 회귀 (0) | 2023.09.13 |
|---|---|
| 1. 순방향 신경망 (0) | 2023.09.13 |
| PyTorch CNN 모델 Fast API로 배포하기 (0) | 2023.09.07 |
| LSTM을 이용한 저수율 예측 (0) | 2023.09.07 |
| 🤗Roberta를 이용한 리뷰 감정분석 (0) | 2023.09.07 |



